Overview
Authors: Anonymous Author(s)
Project Video
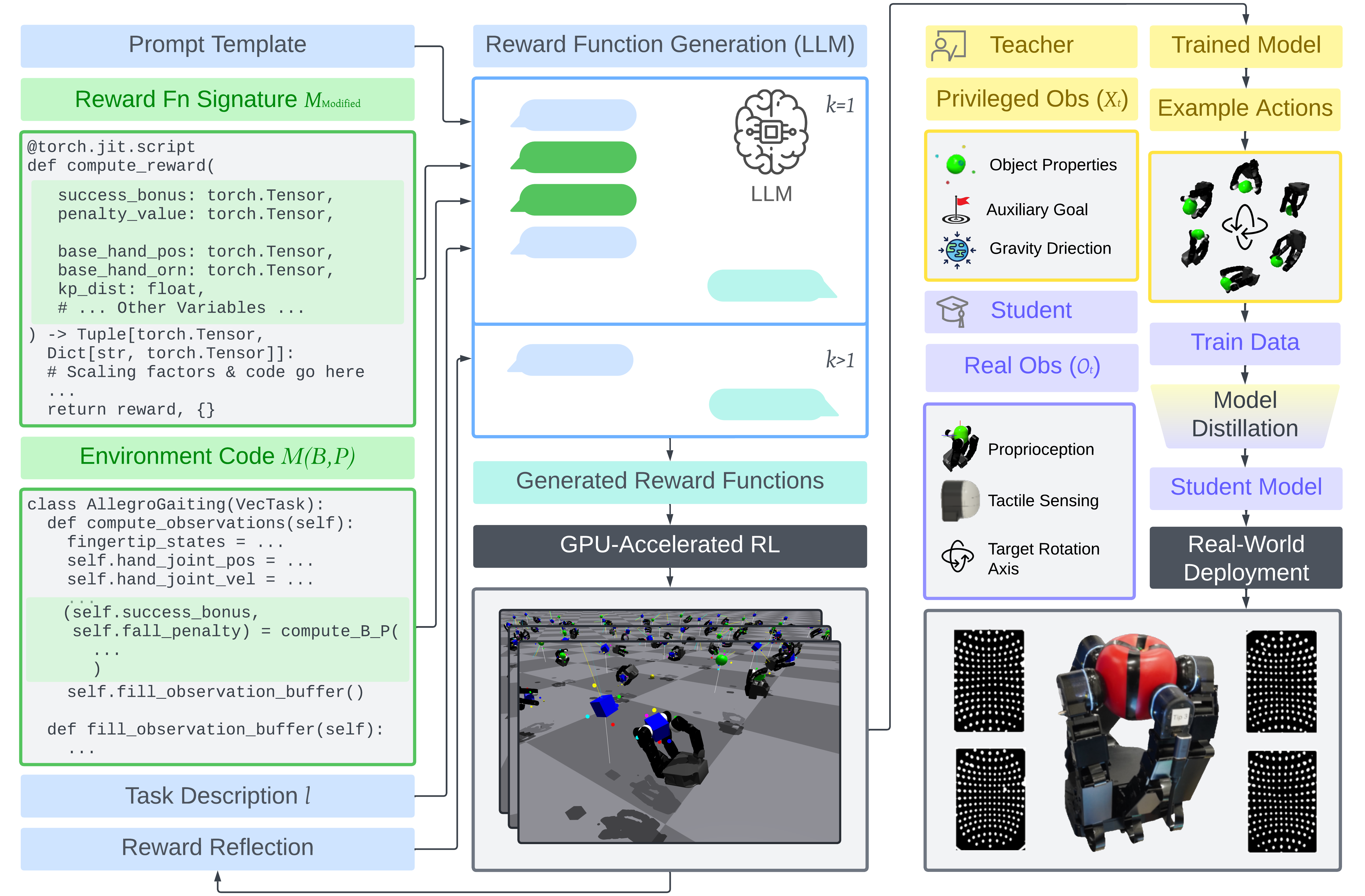
Abstract: Large language models (LLMs) are begining to automate reward design for dexterous manipulation. However, no prior work has considered tactile sensing, which is known to be critical for human-like dexterity. We present Text2Touch, bringing LLM-crafted rewards to the challenging task of multi-axis in-hand object rotation with real-world vision based tactile sensing in palm-up and palm-down configurations. Our prompt engineering strategy scales to over 70 environment variables, and sim-to-real distillation enables successful policy transfer to a tactile-enabled fully actuated four-fingered dexterous robot hand. Text2Touch significantly outperforms a carefully tuned human-engineered baseline, demonstrating superior rotation speed and stability while relying on reward functions that are an order of magnitude shorter and simpler. These results illustrate how LLM-designed rewards can significantly reduce the time from concept to deployable dexterous tactile skills, supporting more rapid and scalable multimodal robot learning.
Reward Functions
Select an approach to view its best reward function code:
// Placeholder reward function code will appear here.
Real-World Policy Videos
Available objects: apple, box, cream, dolphin, duck, lemon, mints, orange, peach, pepper
Rotation axes: x, y, z | Hand orientations: Palm-up (up), Palm-down (down)
Select parameters to view policy videos side by side:
Baseline
GPT-4o
Gemini-1.5-Flash
Deepseek-R1-671B
Key Tables & Results
Prompt Strategies Comparison
| Prompting Strategy | GPT-4o | o3-mini | Gemini-1.5-Flash | Llama3.1-405B | Deepseek-R1-671B | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Rots/Ep | Solve Rate | Rots/Ep | Solve Rate | Rots/Ep | Solve Rate | Rots/Ep | Solve Rate | Rots/Ep | Solve Rate | |
| M(B,P)modified | 5.46 | 84% | 5.38 | 28% | 5.48 | 31% | 5.41 | 10% | 5.08 | 16% |
| M(B, P) | 0.13 | 0% | 0.17 | 0% | 0.04 | 0% | 5.42 | 10% | 5.26 | 16% |
| Mmodified | 0.17 | 0% | 0.17 | 0% | 0.10 | 0% | 0.02 | 0% | 0.05 | 0% |
| M (Original Eureka) | 0.12 | 0% | 0.15 | 0% | 0.05 | 0% | 0.04 | 0% | 0.02 | 0% |
LLM Statistics
| LLM | Performance | Code Quality | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Rots/Ep ↑ | EpLen(s) ↑ | Corr | GR ↑ | Vars ↓ | LoC ↓ | HV ↓ | ||||||
| Best (π*) | Avg | π* | Avg | π* | Avg | π* | Avg | π* | Avg | π* | Avg | |
| Baseline | 4.92 | 4.73 | 27.2 | 26.8 | 1 | - | 66 | - | 111 | - | 2576 | - |
| Gemini‑1.5-Flash | 5.48 | 5.29 | 24.1 | 23.8 | 0.40 | 0.76 | 7 | 6.3 | 24 | 22.6 | 370 | 301 |
| Llama3.1-405B | 5.41 | 5.28 | 23.7 | 23.2 | 0.35 | 0.45 | 5 | 6.6 | 31 | 22.5 | 211 | 233 |
| GPT-4o | 5.46 | 5.20 | 24.4 | 23.4 | 0.30 | 0.63 | 8 | 8.1 | 35 | 26.9 | 317 | 300 |
| o3‑mini | 5.38 | 5.26 | 23.9 | 23.1 | 0.47 | 0.92 | 6 | 6.6 | 27 | 30.1 | 281 | 302 |
| DeepseekR1-671B | 5.26 | 5.12 | 22.9 | 22.4 | 0.42 | 0.93 | 12 | 11.9 | 43 | 45.3 | 994 | 699 |
Distilled Observation Models
| LLM | OOD Mass | OOD Shape | ||
|---|---|---|---|---|
| Rots/Ep ↑ | EpLen(s) ↑ | Rots/Ep ↑ | EpLen(s) ↑ | |
| Baseline | 2.94 | 23.0 | 2.44 | 25.1 |
| Gemini‑1.5-Flash | 3.38 | 19.8 | 2.68 | 21.3 |
| GPT-4o | 3.35 | 20.7 | 2.62 | 22.5 |
| o3‑mini | 3.25 | 19.2 | 2.52 | 21.3 |
| Llama3.1-405B | 3.02 | 18.1 | 2.50 | 20.0 |
| Deepseek-R1-671B | 3.32 | 22.7 | 2.47 | 23.4 |
Real-World Policy Results
| Approach | Palm Up Z | Palm Down Z | Palm Up Y | Palm Down Y | Palm Up X | Palm Down X | Total Avg | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Rot | TTT | Rot | TTT | Rot | TTT | Rot | TTT | Rot | TTT | Rot | TTT | Rot | TTT | |
| Human-engineered Baseline | 1.42 | 22.1 | 0.96 | 17.2 | 1.04 | 23.4 | 0.67 | 24.0 | 1.23 | 19.0 | 0.65 | 14.1 | 0.99 | 20.0 |
| GPT-4o | 2.34 | 26.5 | 1.67 | 23.1 | 1.00 | 27.1 | 0.46 | 16.9 | 0.92 | 14.9 | 0.73 | 15.6 | 1.18 | 20.7 |
| Gemini-1.5-Flash | 2.12 | 26.9 | 1.19 | 19.0 | 1.00 | 26.2 | 0.61 | 27.5 | 1.47 | 21.4 | 1.31 | 21.5 | 1.28 | 23.8 |
| Deepseek-R1-671B | 2.45 | 27.6 | 1.00 | 23.1 | 0.97 | 21.6 | 1.78 | 27.7 | 1.08 | 30.0 | 0.92 | 20.4 | 1.37 | 25.1 |